数理情報工学 / 2007 古文の統計的形態素解析に関する研究
| 氏名 | 原 拓矢 |
|---|---|
| 指導教員 | 田中 久美子 准教授 |
研究概要
自然言語処理の最も基礎的な作業が,文章を構成する単語を得る「形態素解析」である.大規模コーパスの統計に基づく機械学習手法が一般的だが,古文はデータが少なく有意な統計が取れない.そこで現代文の統計を利用し古文の形態素解析を行う手法を提案した.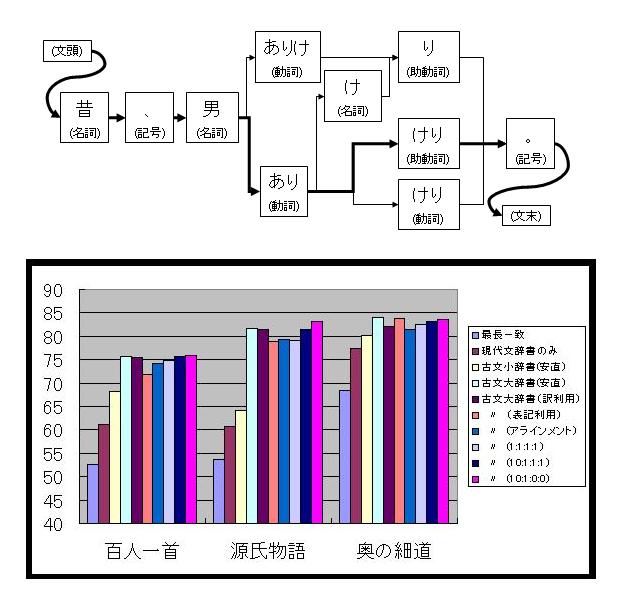
卒論の感想
卒論を通して,研究の進め方を十分学べたと思う.対応単語を得る方法等でまだ試したい点もあるが,短期間の中で充実した研究ができた.この経験を今後の研究に生かしたい.- TOP
- 古文の統計的形態素解析に関する研究